분산 시스템의 장점은?
:분산 시스템은 단일 시스템보다 적은 비용으로 여러 서버에서 사용자 요청을 동시에 처리하 여 높은 성능을 얻어낼 수 있다. 또한 많은 사용자가 동일한 파일에 효과적이고 높은 신뢰 성을 가지고 접근할 수 있게 해준다.
분산 시스템은 왜 미들웨어를 요구하는가?
:분산시스템은 서로 다른 운영체제와 서버 프로그램과의 호환성뿐만 아니라 서로 다른 통신 프로토콜을 사용하는 네트워크간의 접속, 네트워크 자원에 대한 액세스 그리고 시스템을 연 결해 단일한 사용자 환경으로 만들어 이기종 머신들이 한 컴퓨터처럼 함께 동작할 수 있도 록 클라이언트/서버 사이에서 교량적인 역할을 하는 소프트웨어 서비스를 의미한다.
주종 다중 처리기 운영체제 시스템의 구조와 특징을 설명하시오.
:하나의 주 프로세서와 나머지 종 프로세서로 구성된다. 주 프로세서는 입출력과 연 산을 수행하고, 종 프로세서는 연산만을 수행한다. 종 프로세서에서 입출력 발생시 주 프로세서에게 서비스를 요청한다. 주 프로세서의 고장시 전 시스템이 멈춘다. 주 프로세서만이 운영 체제를 수행한다.
다중 프로세서 운영체제의 분리 실행을 설명하시오.
: 각 프로세서가 서로 다른 운영 체제를 가지고 있으며, 각 프로세서에서 발생하는 인터럽 트도 해당 프로세서에서 독립적으로 해결한다.
각 프로세서는 자신만의 파일과 입출력 장치를 제어한다.
각 프로세서는 서로 수행을 서로 돕지 않아 어떤 유휴 상태이고 다른 프로세서는 바쁠 수도 있다. - 한 프로세서의 고장으로 전 시스템이 멈추지 않는다.
분산 시스템에서 요구되는 네 가지 유형의 투명성을 정의하고 각각의 예를 기술하시오
:
위치 투명성은 자원 위치와 각 컴포넌트가 상호작용하는 위치를 사용자가 몰라도 된다. 따 라서, 사용자는 지역 파일에 액세스하듯 원격 파일에 액세스하여 어떤 서버가 해당 파일을 보유하는지 알지 못한다. 예 : 웹페이지, NFS(네트워크 파일 시스템)
고장 투명성은 시스템 구성 요소(컴포넌트)와 통신 오류 때문에 시스템을 수행하는 데 장 애를 받지 않게 한다. 여러 자원이나 컴퓨터에 오류가 발생할 때 시스템 사용자는 성능이 떨어지는 정도만 느낄 수 있다. 오류를 시스템에서 제거하고 재사용할 수 있도록 회복시 켜 준다. 대체로 복제나 복구를 이용하여 구현한다. 복제한 자원 중 하나만 남고 모두 고 장이 나더라도 분산 시스템은 기능을 계속할 수 있다. 예 : 데이터베이스 관리 시스템
중복 투명성은 시스템에 자원 사본이 여러 개 있다는 사실을 감춘다. 동일한 자원이 다수 의 컴퓨터에 있더라도 사용자에게는 자원 하나로만 보이게 한다. 즉, 복제한 자원 그룹에 서 모든 액세스가 자원이 하나만 있는 것처럼 보이게 하여 신뢰성과 유용성을 높일 수 있 다. 예 : 분산 DBMS, 웹페이지 미러링
이동 투명성은 자원을 한 시스템에서 다른 시스템으로 이동해도 사용자가 이를 의식 하지 않고 이용할 수 있도록 하는 것이다. 예를 들어, 파일을 한 서버에서 다른 서버로 이 동하는 것처럼 한 객체를 한 위치에서 다른 위치로 변경할 수 있게 한다. 예 : 웹페이지, NFS
영속 투명성이란 자원이 저장된 위치(메모리나 디스크) 정보를 감춘다.
자원 투명성은 구성 요소에서 자원의 배당과 해제 정보를 감춘다. 자원을 공유하는 데 제 공된다.
트랜잭션투명성은 공유 공간에서 동작하는 트랜잭션 연산 조정과 자원 집합 사이의 결합 을 숨겨 데이터 무결성과 일관성을 확보할 수 있게 한다.
재배치 투명성이란 한 객체의 재배치를 이와 통신하는 다른 객체에 감출 수 있게 한다.
규모 투명성은 구성 요소를 추가하거나 제거하는 등 규모가 바뀌어도 사용자가 의식하지 않는다. 예 : 웹페이지
병행 투명성은 사용자와 응용 프로그램이 서로 간섭 없이 공유 데이터 또는 객체에 동시 에 액세스할 수 있다. 분산 시스템에서 매우 복잡한 메커니즘이 필요하다. 예 : NFS, 금융 자동화 기기 네트워크
2016년 11월 23일 수요일
10강 os
메인 메모리보다 대용량 기억장치에서 파일을 할당하는 비트맵을 사용해야하는 이유는?
: 비트 맵이 메인 메모리에 저장되면 시스템 고장(메모리 오류)인 경우라도 빈 공간 리스트가 손실 되지 않는다
연속 할당 정책,연결 할당 정책, 인덱스 할당 정책을 지원하는 시스템이 있다. 할당 정책을 선택하는 기준과 특정 파일에서는 어떤 할당 정책을 이용해야 하는지 설명하시오.
:
연속 할당은 디스크에 연속적인 주소에 할당을 하며 연결할당은 각 파일들은 디스크 블록들의 리스트가 연결되어있어 순차적으로 엑세스가 되어있다.인덱스 할당 정책은 모든 포인터를 인덱스 블록이라는 하나의 장소에서 관리하여 직접 액세스를 지원한다.
파일의 엑세스 속도에서 할당 방법을 평가한다면?
:연속 할당이 가장 빠르다. 디스크 헤드가 파일의 액세스 사이를 이동해야 할 수도 있기 때 문에 링크는 느리다. 전체 인덱스가 항상 메모리에 보존 할 수없는 경우 인덱스 할당은 최저 이다. 그렇지 않다면, 파일 인덱스의 다음 블록을 액세스 할 때 추가 시간이 필요하다.
각 디스크 블록이 8KB(213바이트)인 128GB(237바이트) 디스크의 파일 시스템이 있는 컴퓨터를 가정하자. 이 컴퓨터의 운영체제가 FAT를 사용할 때 FAT가 사용하는 최소 메모리 크기는?
:각 디스크 블록에 FAT 항목이 있으므로 디스크는 237바이트, 디스크 블록은 213바이트이다. 따라서 디스크 블록의 수 즉 FAT 항목 수는 237/213 = 224이다. 그러므로 224 항목에 대한 블록 번호(디스크 주소)는 log(224) = 24비트 즉 최소 3바이트를 필요로 한다. FAT에 의해 점유 된 공간의 최소 크기는 항목당 3바이트이므로 224 ☓ 3 = 16MB ☓ 3 = 48MB
파일을 포함한 디스크 블록을 구성하는 많은 방법이 있다. 다음 물음에 답하시오.
1) 연속 할당이 인덱스 할당보다 어떤 장점이 있는지 설명하시오
:인덱스 블록은 메모리가 많이 필요하지만 연속 할당은 인덱스 구조의 복잡한 대신 첫 번째 블록과 길이에 대한 포인터만 저장하므로 단순하다. 또, 다음 블록 에 대한 포인터를 얻기 위해 다시 인덱스 계속 할 필요가 없으므로 파일 액 세스에 빠르다.
2)인덱스 할당이 연속 할당보다 어떤 장점이 있는지 설명하시오
:인덱스 할당은 큰 연속 공간에 대한 필요성이 없기 때문에 파일 공간 확장이 쉽고 연속 할 당 가능하고 외부 단편화를 방지할 수 있다.
디스크 크기가 40GB라고 하자. 파일에서 다음 블록의 블록 번호 4바이트가 필요로 하고, 기타 데이터 2바이트가 필요로 한다면 각 블록의 크기가 1K일때 FAT 테이블 크기는?
:디스크 블록 수 = FAT 의 항목 수 = 40GB/1KB = 40 ☓ 1024 ☓ 1024
FAT 크기= 6 ☓ 40 ☓1024 ☓1014 = 240MB
: 비트 맵이 메인 메모리에 저장되면 시스템 고장(메모리 오류)인 경우라도 빈 공간 리스트가 손실 되지 않는다
연속 할당 정책,연결 할당 정책, 인덱스 할당 정책을 지원하는 시스템이 있다. 할당 정책을 선택하는 기준과 특정 파일에서는 어떤 할당 정책을 이용해야 하는지 설명하시오.
:
연속 할당은 디스크에 연속적인 주소에 할당을 하며 연결할당은 각 파일들은 디스크 블록들의 리스트가 연결되어있어 순차적으로 엑세스가 되어있다.인덱스 할당 정책은 모든 포인터를 인덱스 블록이라는 하나의 장소에서 관리하여 직접 액세스를 지원한다.
파일의 엑세스 속도에서 할당 방법을 평가한다면?
:연속 할당이 가장 빠르다. 디스크 헤드가 파일의 액세스 사이를 이동해야 할 수도 있기 때 문에 링크는 느리다. 전체 인덱스가 항상 메모리에 보존 할 수없는 경우 인덱스 할당은 최저 이다. 그렇지 않다면, 파일 인덱스의 다음 블록을 액세스 할 때 추가 시간이 필요하다.
각 디스크 블록이 8KB(213바이트)인 128GB(237바이트) 디스크의 파일 시스템이 있는 컴퓨터를 가정하자. 이 컴퓨터의 운영체제가 FAT를 사용할 때 FAT가 사용하는 최소 메모리 크기는?
:각 디스크 블록에 FAT 항목이 있으므로 디스크는 237바이트, 디스크 블록은 213바이트이다. 따라서 디스크 블록의 수 즉 FAT 항목 수는 237/213 = 224이다. 그러므로 224 항목에 대한 블록 번호(디스크 주소)는 log(224) = 24비트 즉 최소 3바이트를 필요로 한다. FAT에 의해 점유 된 공간의 최소 크기는 항목당 3바이트이므로 224 ☓ 3 = 16MB ☓ 3 = 48MB
파일을 포함한 디스크 블록을 구성하는 많은 방법이 있다. 다음 물음에 답하시오.
1) 연속 할당이 인덱스 할당보다 어떤 장점이 있는지 설명하시오
:인덱스 블록은 메모리가 많이 필요하지만 연속 할당은 인덱스 구조의 복잡한 대신 첫 번째 블록과 길이에 대한 포인터만 저장하므로 단순하다. 또, 다음 블록 에 대한 포인터를 얻기 위해 다시 인덱스 계속 할 필요가 없으므로 파일 액 세스에 빠르다.
:인덱스 할당은 큰 연속 공간에 대한 필요성이 없기 때문에 파일 공간 확장이 쉽고 연속 할 당 가능하고 외부 단편화를 방지할 수 있다.
디스크 크기가 40GB라고 하자. 파일에서 다음 블록의 블록 번호 4바이트가 필요로 하고, 기타 데이터 2바이트가 필요로 한다면 각 블록의 크기가 1K일때 FAT 테이블 크기는?
:디스크 블록 수 = FAT 의 항목 수 = 40GB/1KB = 40 ☓ 1024 ☓ 1024
FAT 크기= 6 ☓ 40 ☓1024 ☓1014 = 240MB
2016년 11월 16일 수요일
동사
동사에는 여러 종류가 있는데 그 중 하나엔 be동사가 있다.
be동사는 be동사 + 전치사(부사)로 표현된다.
이런 방식으로 여러가지 표현으로 되어 어려운 단어를 대신하는 경우가 많다.
애매하게 뭔가 표현을 하고 싶은데 하기 힘든 경우 be동사와 전치사로 해결되는 것이 많다.
예를 들자면 불이 켜지다같은 경우 turn on으로 표현하기보단 be+ on으로 표현을 할 수 있고
취소되다고 cancle보단 off으로 쓰곤 한다.
글을 쓸때는 어려운 단어를 쓰더라도 말할때는 be동사로 간편하게 말하자.
다른 동사 사용법에 대해 말하자
예를 들어서 그는 춤을 잘춥니다를 영어로 표현하면 어떨까?
He is a good dancer가 맞다.
다른 표현이 틀린건 아니다. 단지 좀 더 영어식 표현이라는 거다.
형용사 + 명사 구조를 더 선호한다는 거다.
영어가 명사를 좋아하다보니 have,give를 더 많이 사용하다보니 사물이 아닌 것도 가지고 줄 수 있는 소유의 대상으로 표현을 한다.
예를 들어보면 have a long face 또는 have poor eyesight 이렇게 사용이 된다는 거다.
추가적으로 말하자면 우리나라 말은 한자표현이 많다.
한자는 글자마다 뜻을 갖고있어 의미가 압축적으로 표현된다.
일대일로 대응하는 우리말을 찾기란 쉽지않다.
한자 표현을 영어로 쉽게 표현하기 위해서는 먼저 그 표현을 쉬운 우리말 뜻을 풀어내는 것이 좋다.
순수 우리말의 경우도 우리말을 그대로 영어로 표현하지 말고 핵심적인 내용을 담아 풀어서 말하려는 훈련을 해보자.
be동사는 be동사 + 전치사(부사)로 표현된다.
이런 방식으로 여러가지 표현으로 되어 어려운 단어를 대신하는 경우가 많다.
애매하게 뭔가 표현을 하고 싶은데 하기 힘든 경우 be동사와 전치사로 해결되는 것이 많다.
예를 들자면 불이 켜지다같은 경우 turn on으로 표현하기보단 be+ on으로 표현을 할 수 있고
취소되다고 cancle보단 off으로 쓰곤 한다.
글을 쓸때는 어려운 단어를 쓰더라도 말할때는 be동사로 간편하게 말하자.
다른 동사 사용법에 대해 말하자
예를 들어서 그는 춤을 잘춥니다를 영어로 표현하면 어떨까?
He is a good dancer가 맞다.
다른 표현이 틀린건 아니다. 단지 좀 더 영어식 표현이라는 거다.
형용사 + 명사 구조를 더 선호한다는 거다.
영어가 명사를 좋아하다보니 have,give를 더 많이 사용하다보니 사물이 아닌 것도 가지고 줄 수 있는 소유의 대상으로 표현을 한다.
예를 들어보면 have a long face 또는 have poor eyesight 이렇게 사용이 된다는 거다.
추가적으로 말하자면 우리나라 말은 한자표현이 많다.
한자는 글자마다 뜻을 갖고있어 의미가 압축적으로 표현된다.
일대일로 대응하는 우리말을 찾기란 쉽지않다.
한자 표현을 영어로 쉽게 표현하기 위해서는 먼저 그 표현을 쉬운 우리말 뜻을 풀어내는 것이 좋다.
순수 우리말의 경우도 우리말을 그대로 영어로 표현하지 말고 핵심적인 내용을 담아 풀어서 말하려는 훈련을 해보자.
2016년 11월 15일 화요일
주어-(1)
영어를 말하는데 애를 먹는 것중 하나가 주어이다.
주어를 말할때 영어와 한국어가 표현이 다른 경우가 많기 때문에 애를 먹는데
첫번째로, 우리말은 주어가 생략되더라도 의미가 통하지만 영어는 주어를 생략하면 아니된다. 우리말은 주어를 쓰지 않아도 틀린 문장이 아니며, 오히려 주어를 쓰지 않아야 더 자연스럽게 들린다.
Do you have plans?
Can i eat these cookies?
이 문장들을 해석해보거라. 전부 다 해석하면 첫번째 문장은 당신 약속 있나요? 이렇게 해석할 수 있고 두번째 문장은 제가 이 쿠키를 먹어도 되나요? 이렇게 해석된다.
그런데 이 문장에서 주어를 해석하지 않아야 좀 더 자연스럽게 해석된다.
때로는 주어가 다르게 해석되기도 한다.
They serve good steak
You can see the beach from here
우리 말은 장소를 나타내는 거기라던지 여기라는 말로 해석이되기 때문이다.
무엇보다도 우리나라 말은 은/는/이/가 가 붙으면 주어로 생각하지만, 영어는 동사를 직접 행하는 명사가 주어 자리에 주로 온다는 점을 알아야한다.
영어에는 우리말과 달리 물주구문이 발달해 있다.
물주구문이란 사물이 주어로 쓰이는 문장을 말한다.
물론 우리말도 사물이 주어가 되는 경우는 많지만 영어는 have,give 등의 동사와 빈번하게 함께 쓰여서 사물 주어가 마치 사람 주어처럼 의지를 가진 것처럼 의지를 가진것 처럼 표현되는 점이다.
This camera has a zoom lens
This room has a great view
it gives me a headache
이렇게 사물주어는 부사의 형태로 표현되는 경우도 많다.
가장 좋은 예가 What이다.
what brings you here
이런 사물 주어가 가지는 특징은 의지가 없는 사물을 주체로 표현한다는 것으로 우리말로 해석하면 어색한 표현이 많다는 것이다. 그냥 영어는 영어로 받아들이자.
주어를 말할때 영어와 한국어가 표현이 다른 경우가 많기 때문에 애를 먹는데
첫번째로, 우리말은 주어가 생략되더라도 의미가 통하지만 영어는 주어를 생략하면 아니된다. 우리말은 주어를 쓰지 않아도 틀린 문장이 아니며, 오히려 주어를 쓰지 않아야 더 자연스럽게 들린다.
Do you have plans?
Can i eat these cookies?
이 문장들을 해석해보거라. 전부 다 해석하면 첫번째 문장은 당신 약속 있나요? 이렇게 해석할 수 있고 두번째 문장은 제가 이 쿠키를 먹어도 되나요? 이렇게 해석된다.
그런데 이 문장에서 주어를 해석하지 않아야 좀 더 자연스럽게 해석된다.
때로는 주어가 다르게 해석되기도 한다.
They serve good steak
You can see the beach from here
우리 말은 장소를 나타내는 거기라던지 여기라는 말로 해석이되기 때문이다.
무엇보다도 우리나라 말은 은/는/이/가 가 붙으면 주어로 생각하지만, 영어는 동사를 직접 행하는 명사가 주어 자리에 주로 온다는 점을 알아야한다.
영어에는 우리말과 달리 물주구문이 발달해 있다.
물주구문이란 사물이 주어로 쓰이는 문장을 말한다.
물론 우리말도 사물이 주어가 되는 경우는 많지만 영어는 have,give 등의 동사와 빈번하게 함께 쓰여서 사물 주어가 마치 사람 주어처럼 의지를 가진 것처럼 의지를 가진것 처럼 표현되는 점이다.
This camera has a zoom lens
This room has a great view
it gives me a headache
이렇게 사물주어는 부사의 형태로 표현되는 경우도 많다.
가장 좋은 예가 What이다.
what brings you here
이런 사물 주어가 가지는 특징은 의지가 없는 사물을 주체로 표현한다는 것으로 우리말로 해석하면 어색한 표현이 많다는 것이다. 그냥 영어는 영어로 받아들이자.
2016년 11월 14일 월요일
의문문(2)
수동태 문장
수동태란 본래 문장의 핵심을 목적어에 주는 형태를 말한다. 쉽게 말해서 우리가 말하는 능동태는 어느 대상의 시점에서 문장을 이끌어 나간다. 그래서 이때 주어는 스스로 행위를 할 수 있는 대상이 된다. 이런 문장의 주체를 목적의 대상으로 바꾸게 되는 것이 수동태이다.
솔직히 다 필요없고 수동태는 수동태로 보는게 맞다. 그런데 이렇게 설명한 이유는 다른게 아니라 좀 더 이해하기 쉬우라고 한거다.
주어와 동사의 관계가 수동일 때 쓰인다. 형태는 Be동사 + P.P이다.
예시를 들자면 A woman was killed on the street yesterday
This dress is made of cotton
이렇게 쓰인다.
거의 이렇게 쓰이지는 않지만 새로운 정보를 제시 할 때는 수동태와 함께 by+행위자를 쓰기도 한다.
Who directed the movie?
It was directed by Spielberg
이렇게 by를 써서 ~에 의하여 이렇게 해석을 할수 있다.
가정법은 현재의 사실에 반대되거나 이루지지 않은 사실을 말할때 말한다.
당연한거겠지만....
우선 현실의 현재는 가상의 과거시제로 나타낸다. 따라서 if+주어+과거동사, 주어+would(조동사)+원형으로 나타낸다.
예시를 들자면 if had time, I would help you
if i were you, i wouldn't go there.
과거에 있었던 현실을 반대로 가정하는 경우, 현실의 과거를 가상의 과거 완료시제로 나타낸다.
if +주어+과거완료, 주어 + would+ have+p.p로 나타낸다.
if I had had time, i would have helped you
if i had been you, i would not have gone there
이를 볼때 가정법은 말하고자 하는 시제 보다 이전의 시대를 가정하여 그 상황을 역설하는 방식이라 하겠다.
수동태란 본래 문장의 핵심을 목적어에 주는 형태를 말한다. 쉽게 말해서 우리가 말하는 능동태는 어느 대상의 시점에서 문장을 이끌어 나간다. 그래서 이때 주어는 스스로 행위를 할 수 있는 대상이 된다. 이런 문장의 주체를 목적의 대상으로 바꾸게 되는 것이 수동태이다.
솔직히 다 필요없고 수동태는 수동태로 보는게 맞다. 그런데 이렇게 설명한 이유는 다른게 아니라 좀 더 이해하기 쉬우라고 한거다.
주어와 동사의 관계가 수동일 때 쓰인다. 형태는 Be동사 + P.P이다.
예시를 들자면 A woman was killed on the street yesterday
This dress is made of cotton
이렇게 쓰인다.
거의 이렇게 쓰이지는 않지만 새로운 정보를 제시 할 때는 수동태와 함께 by+행위자를 쓰기도 한다.
Who directed the movie?
It was directed by Spielberg
이렇게 by를 써서 ~에 의하여 이렇게 해석을 할수 있다.
가정법은 현재의 사실에 반대되거나 이루지지 않은 사실을 말할때 말한다.
당연한거겠지만....
우선 현실의 현재는 가상의 과거시제로 나타낸다. 따라서 if+주어+과거동사, 주어+would(조동사)+원형으로 나타낸다.
예시를 들자면 if had time, I would help you
if i were you, i wouldn't go there.
과거에 있었던 현실을 반대로 가정하는 경우, 현실의 과거를 가상의 과거 완료시제로 나타낸다.
if +주어+과거완료, 주어 + would+ have+p.p로 나타낸다.
if I had had time, i would have helped you
if i had been you, i would not have gone there
이를 볼때 가정법은 말하고자 하는 시제 보다 이전의 시대를 가정하여 그 상황을 역설하는 방식이라 하겠다.
2016년 11월 7일 월요일
9강 os
입출력 모듈의 기능을 간략하게 설명하시오
: 입출력 모듈 기능은 프로세서가 여러 입출력 장치를 쉽게 제어하도록 하는데 목적이 있다.
이를 위해 첫쨰로 내부 자원과 데이터 입출력 등 다양한 동작을 제어하고 타이밍 기능을 제공한다. 둘째로 프로세서에서 명령을 전달 받고 관련된 메세지를 인식하는 기능을 제공하며 버퍼링을 이용하여 전송속도를 조절한다. 마지막으로 오류를 검출하는 기능을 제공한다.
DMA를 설명하시오
:DMA란 프로세서의 도움없이 직접 메인 메모리를 제어하여 데이터를 전송하는 형태를 말하며 데이터를 DMA제어기에 전달하여 입출력을 요청하면 이를 직접 처리하는데 즉, 입출력장치에서 메모리로 데이터를 블록단위로 전송 할 수 있다.
DMA 방법은 어떻게 병렬 처리 시스템의 성능을 향상시키는가? 하드웨어 설계가 복잡해지는 이유는?
: DMA 제어기가 데이터를 전송하는 동안 프로세서는 다른 작업을 수행할 수 있어 스틸링이 이루어 지게 된다. 스틸링은 입출력 작업을 DMA에 전담 시키기 때문에 시스템의 전체성능은 올라간다. 이 하드웨어 디자인 하는 것은 DMA제어기가 그 시스템으로 통합되야만 하고 그 통합된 시스템은 DMA 제어기가 버스 마스터가 되어야 하기 때문에 복잡하다.
디스크 엑세스 시간(속도)을 결정하는 요소는?
:탐색시간과 회전 지연시간, 전송시간이다. 이동 디스크 데이터 액세스시간은 탐색시간과 회전 지연시간, 전송시간을 더한 값이며 고정헤드의 디스크 시스템의 값은 회전 지연시간과 전송시간의 합이다.
디스크 입출력에 필요한 정보는?
:입력 동작인지, 출력 동작인지 하는 정보. 디스크 주소. 메모리 주소. 전송할 정보의 총량.
프로세스 속도를 높일 때 시스템 버스와 장치 속도 크기를 증가 시켜야 하는 이유는? 입출력에 50%와 연산 50%를 수행하는 하나의 시스템을 고려하여 설명하시오
:프로세서 수행을 더블링(doubling)하는 것은 전체 시스템 수행을 단지 50% 까지 증가시킬 것이다. 두 개의 시스템측면들을 더블링하면 수행을 100%까지 증가시킬 것 이다. 일반적으로, 개별적인 시스템 구성요소들의 수행을 증가시키는 것보다 최근 시스템 병 목현상을 제거하고, 전체시스템 수행을 증가시키는 것이 중요하다
디스크 스케줄링 방법 중 최소 탐색시간 우선 스케줄링을 설명하시오
:디스크 요청을 처리하려고 헤드가 먼 곳까지 이동하기 전에 현재 헤드 위치에 가까운 모든 요구를 먼저 처리하는 방법이다.
최소 탐색 시간 우선 스케줄링은 실린더의 너무 안쪽이나 바깥쪽 보다 중간쯤이 좋다. 그 이유를 설명하시오
:디스크의 중심은 모든 다른 트랙들에 대해 가장 작은 평균적인 거리에 위치한다. 그러므로 그 알고리즘이 첫 번째 요청을 서비스 한 후에는 또 다른 특정한 트랙보다 좀 더 중심트랙 에 가까워지며 그 결과 그 알고리즘은 처음 그 위치로 더 자주 가게 된다.
선입선처리 스케줄링의 문제점은?
:서비스지연을 감소시키는 요청을 재정렬하지 않아서 임의의 탐색 패턴결과로 탐색시간이 증가하면서 처리량이 감소시키는 단점이 있다.
단일 사용자 환경에서 선입선처리외의 스케줄링이 유용한가?
:단일 사용자한경에서, 그 I/O 대기행렬(queue)은 대개 길이가 1이다. 그러므로 선입선처리 (FCFS)는 디스크를 스캐줄링하는 가장 경제적인 방법이다.
C-SCAN방법은 Scan방법을 어떻게 변경한 것인가?
:가장 높은 트랙수에 도달한 후에는, 어떤 경로도 거치지 않고 가장 낮은 트랙수를 요청하도록 변경된다. 대기 시간을 좀 더 균등하게 하려고 스캔 알고지음을 변형시킨 알고리즘이다. 스캔 스캐줄링과 같이 한쪽 방향으로 헤드를 이동해 가면서 요청을 처리하지만 한쪽 끝에 다다르면 반대 방향으로 헤드를 이동하는 것이 아니라 다시 처음부터 처리를 한다. 따라서 CSCAN은 처음과 마지막 트랙을 서로 인접시킨 것과 같은 원형처럼 디스크 처리하므로 처리량을 향상시키면서 바깥 트랙과 안쪽 트랙에 대한 차별이 없어 반응 시간의 변화를 줄이는 효과를 준다.
다음과 같은 선형 요청 디스크 큐가 있다. ①~③의 디스크 스케줄링 알고리즘에서 트랙의 헤드 이동수는?
:

①FIFO
: 15 + 2 + 44 + 37 + 20 + 30 + 11 + 32 + 52 + 50 =393
②SSFT
: 15 + 2 + 7 + 10 + 11 + 16 + 4 + 50 + 2 + 9 =126
③LOOK
:15 + 5 + 37 + 16 + 11 + 17 + 4 + 9 + 11 + 50 =175
RAID를 사용할 때의 장점, RAID의 0~3계층 까지 구조와 차이점을 비교 설명하시오.
:운영체제로 여러대의 물리적 디스크를 하나의 논리적 디스크로 인식하는 기술로 프로세서의 성능을 향상된다.
RAID 0는 데이터를 여러 개의 디스크 드라이브에 분산하는 구조로 여러개의 디스크 드라이브를 동시에 액세스함으로써 성능 개선이 가능하다.
RAID 1은 0와 같은 방식으로 각 디스크 드라이브 에 대해 별도의 백업 드라이브를 운영된다.
RAID 2는 워드 단위로 운영 워드를 니브단위로 나누어 각 비트별로 다른 디스크 드라이브에 저장되며, 그 비트에 대해 해밍코드 3비트를 생성하여 이 코드로 각기 다른 드라이브에 1비트씩 배치한다.
RAID 3는 2의 간소화 버전으로 3비트의 해밍코드 대신 1 비트의 패리티비트를 사용한다.
: 입출력 모듈 기능은 프로세서가 여러 입출력 장치를 쉽게 제어하도록 하는데 목적이 있다.
이를 위해 첫쨰로 내부 자원과 데이터 입출력 등 다양한 동작을 제어하고 타이밍 기능을 제공한다. 둘째로 프로세서에서 명령을 전달 받고 관련된 메세지를 인식하는 기능을 제공하며 버퍼링을 이용하여 전송속도를 조절한다. 마지막으로 오류를 검출하는 기능을 제공한다.
DMA를 설명하시오
:DMA란 프로세서의 도움없이 직접 메인 메모리를 제어하여 데이터를 전송하는 형태를 말하며 데이터를 DMA제어기에 전달하여 입출력을 요청하면 이를 직접 처리하는데 즉, 입출력장치에서 메모리로 데이터를 블록단위로 전송 할 수 있다.
DMA 방법은 어떻게 병렬 처리 시스템의 성능을 향상시키는가? 하드웨어 설계가 복잡해지는 이유는?
: DMA 제어기가 데이터를 전송하는 동안 프로세서는 다른 작업을 수행할 수 있어 스틸링이 이루어 지게 된다. 스틸링은 입출력 작업을 DMA에 전담 시키기 때문에 시스템의 전체성능은 올라간다. 이 하드웨어 디자인 하는 것은 DMA제어기가 그 시스템으로 통합되야만 하고 그 통합된 시스템은 DMA 제어기가 버스 마스터가 되어야 하기 때문에 복잡하다.
디스크 엑세스 시간(속도)을 결정하는 요소는?
:탐색시간과 회전 지연시간, 전송시간이다. 이동 디스크 데이터 액세스시간은 탐색시간과 회전 지연시간, 전송시간을 더한 값이며 고정헤드의 디스크 시스템의 값은 회전 지연시간과 전송시간의 합이다.
디스크 입출력에 필요한 정보는?
:입력 동작인지, 출력 동작인지 하는 정보. 디스크 주소. 메모리 주소. 전송할 정보의 총량.
프로세스 속도를 높일 때 시스템 버스와 장치 속도 크기를 증가 시켜야 하는 이유는? 입출력에 50%와 연산 50%를 수행하는 하나의 시스템을 고려하여 설명하시오
:프로세서 수행을 더블링(doubling)하는 것은 전체 시스템 수행을 단지 50% 까지 증가시킬 것이다. 두 개의 시스템측면들을 더블링하면 수행을 100%까지 증가시킬 것 이다. 일반적으로, 개별적인 시스템 구성요소들의 수행을 증가시키는 것보다 최근 시스템 병 목현상을 제거하고, 전체시스템 수행을 증가시키는 것이 중요하다
디스크 스케줄링 방법 중 최소 탐색시간 우선 스케줄링을 설명하시오
:디스크 요청을 처리하려고 헤드가 먼 곳까지 이동하기 전에 현재 헤드 위치에 가까운 모든 요구를 먼저 처리하는 방법이다.
최소 탐색 시간 우선 스케줄링은 실린더의 너무 안쪽이나 바깥쪽 보다 중간쯤이 좋다. 그 이유를 설명하시오
:디스크의 중심은 모든 다른 트랙들에 대해 가장 작은 평균적인 거리에 위치한다. 그러므로 그 알고리즘이 첫 번째 요청을 서비스 한 후에는 또 다른 특정한 트랙보다 좀 더 중심트랙 에 가까워지며 그 결과 그 알고리즘은 처음 그 위치로 더 자주 가게 된다.
선입선처리 스케줄링의 문제점은?
:서비스지연을 감소시키는 요청을 재정렬하지 않아서 임의의 탐색 패턴결과로 탐색시간이 증가하면서 처리량이 감소시키는 단점이 있다.
단일 사용자 환경에서 선입선처리외의 스케줄링이 유용한가?
:단일 사용자한경에서, 그 I/O 대기행렬(queue)은 대개 길이가 1이다. 그러므로 선입선처리 (FCFS)는 디스크를 스캐줄링하는 가장 경제적인 방법이다.
C-SCAN방법은 Scan방법을 어떻게 변경한 것인가?
:가장 높은 트랙수에 도달한 후에는, 어떤 경로도 거치지 않고 가장 낮은 트랙수를 요청하도록 변경된다. 대기 시간을 좀 더 균등하게 하려고 스캔 알고지음을 변형시킨 알고리즘이다. 스캔 스캐줄링과 같이 한쪽 방향으로 헤드를 이동해 가면서 요청을 처리하지만 한쪽 끝에 다다르면 반대 방향으로 헤드를 이동하는 것이 아니라 다시 처음부터 처리를 한다. 따라서 CSCAN은 처음과 마지막 트랙을 서로 인접시킨 것과 같은 원형처럼 디스크 처리하므로 처리량을 향상시키면서 바깥 트랙과 안쪽 트랙에 대한 차별이 없어 반응 시간의 변화를 줄이는 효과를 준다.
다음과 같은 선형 요청 디스크 큐가 있다. ①~③의 디스크 스케줄링 알고리즘에서 트랙의 헤드 이동수는?
:
①FIFO
: 15 + 2 + 44 + 37 + 20 + 30 + 11 + 32 + 52 + 50 =393
②SSFT
: 15 + 2 + 7 + 10 + 11 + 16 + 4 + 50 + 2 + 9 =126
③LOOK
:15 + 5 + 37 + 16 + 11 + 17 + 4 + 9 + 11 + 50 =175
:운영체제로 여러대의 물리적 디스크를 하나의 논리적 디스크로 인식하는 기술로 프로세서의 성능을 향상된다.
RAID 0는 데이터를 여러 개의 디스크 드라이브에 분산하는 구조로 여러개의 디스크 드라이브를 동시에 액세스함으로써 성능 개선이 가능하다.
RAID 1은 0와 같은 방식으로 각 디스크 드라이브 에 대해 별도의 백업 드라이브를 운영된다.
RAID 2는 워드 단위로 운영 워드를 니브단위로 나누어 각 비트별로 다른 디스크 드라이브에 저장되며, 그 비트에 대해 해밍코드 3비트를 생성하여 이 코드로 각기 다른 드라이브에 1비트씩 배치한다.
RAID 3는 2의 간소화 버전으로 3비트의 해밍코드 대신 1 비트의 패리티비트를 사용한다.
2016년 11월 1일 화요일
8강 os
요구 페이징과 프리 페이징을 설명하시오
:요구 페이징은 필요한 프로그램만 메모리에 적재하는 방법으로 페이지들이 싱행하는 과정에서 실제로 필요해질 때 적재한다. 프로그램을 실행하려고 프로그램의 일부만 메인 메모리에 저재하되, 순차적으로 작성되어 있는 프로그램의 모두 모듈을 처리할 때 다른 부분은 실행하지 않는다. 프리 페이징은 처음에 발생하는 많은 페이지 부재를 방지하는 방법으로, 예상되는 모든 페이지를 사전에 한꺼번에 메모리 내로 가져온다.
요구 페이징의 장점을 열거하시오
:다중 프로그래밍의 정도를 증가시키고 액세스 하지 않은 페이지를 적재하지 않으므로, 다른 프로그램도 사용할수 있도록 메모리를 절약할 수 있다.
프로그램을 시작할 때 적재시간을 줄일 수 있다.
적은 수의 페이지를 읽기 때문에 초기 디스크 오버헤드가 적다.
페이지 부재를 디스크에서 페이지를 로드하는 데 사용할 수 있어 페이징 시스템보다 하드웨어 지원이 추가로 필요하지 않다.
적재된 페이지 중 하나를 수정할 때 까지 페이지들은 여러 프로그램이 공유 하므로 쓰기복사 기술로 더 많은 자원을 저장할 수 있다.
프로그램을 실행할 충분한 메모리가 없는 시스템에서도 대용량 프로그램을 실행 할 수 있으며, 프로그래머는 오버레이보다 쉽게 구현 할 수 있다.
페이지 부재란 무엇인지 설명하시오
:프로세스가 메인 메모리에 적재 되지 않은 페이지를 액세스 할때 하드웨어가 제기 하는 소프트웨어 트랩이다.
페이지 부재를 수행하는 여섯 단계를 열거하시오
:
프로세스 제어 블록에 있는 내부 테이블을 검사하여 프로세스가 메모리 액세스에 타당한지를 결정한다.
프로세스 참조가 무효화되었으면 프로세스가 중단되고, 유효한 페이지면 명령을 계속 처리하나 유효하지 않은 페이지면 페이지를 메모리에 가져와야한다.
메모리에서 빈 프레임 중 하나를 선택한다.
요구된 프레임에 요구된 페이지에 입출력하는 동안 프로세서는 다른 프로세스의 디스크 동작을 스케줄링 한다.
요구된 페이지가 메모리에 있다는것을 알리기 위해 페이지 테이블의 비타당 비트를 타당으로 변경한다.
주소 트랩으로 인터럽트 된 명령어를 다시 시작한다.
페이지 대치란 무엇인지 설명하시오
:페이지 부재가 발생하면, 메인 메모리에 있으면서 사용하지 않는 페이지를 없애 새로운 페이지로 바뀌는 작업이다.
스래싱이란 무엇인지 설명하시오
:페이지 교환이 계속 일어나는 현상이다.
작업 집합 모델의 장점을 설명하시오
:프로세스가 많이 참조하는 페이지 집합을 메모리 공간에 계속 상주시켜 빈번한 페이지 대치 현상을 줄인다.
단순 페이지 시스템을 다음 매개변수 관점에서 살펴보자
:
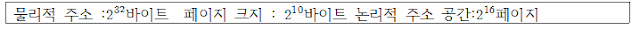 ①논리적 주소에서 몇 개의 비트가 있는가?
①논리적 주소에서 몇 개의 비트가 있는가?
:논리적 주소의 크기가 16비트이고 페이지의 크기는 10바트 이므로 총 26비트이다.
②프레임에 몇 개의 바이트가 있는가?
:하나의 프레임은 하나의 페이지와 같으므로 10바이트이다.
③물리적 주소에서 프래임을 나타내는 비트는 몇개인가?
:물리적 주소에서 페이지 크기를 나누므로 32비트-10비트 즉 22비트이다.
④페이지 테이블에 있는 항목들은 몇개인가?
:논리적 주소에는 각 페이지에 해당하는 하나의 항목이 있다. 따라서 2의 16승만큼의 항목들이 있다.
⑤각 페이지 테이블 항목에 몇 개의 비트가 있는가?(단, 각 테이블 항목은 유효,무효 비트를 포함하고 있다고 가정한다.)
:페이지 테이블이 16비트이므로 15비트의 프레임이 있다.
프리 페이징을 사용하는 이유를 설명하시오
:입출력 인터럽트를 위해 연속된 페이지를 한 번에 메모리로 가져오기 때문에 입출력을 여러 번 수행하는 요구 페이지보다 더 성능이 좋기 때문이다.
페이지 크기를 결정하는 요소를 열거하시오
:페이지 테이블의 크기,프로세스 메모리의 크기, 내부 단편화,입출력 시간 최소화,페이지 부재
다음 페이지 참조열에서 ①~③의 대치 알고리즘에 페이지 부재가 몇개 일어나는가?(단, 페이지 프레임은 4개로 가정한다.)

①LRU:10회

②FIFO;9회

③Optimal:7회

:요구 페이징은 필요한 프로그램만 메모리에 적재하는 방법으로 페이지들이 싱행하는 과정에서 실제로 필요해질 때 적재한다. 프로그램을 실행하려고 프로그램의 일부만 메인 메모리에 저재하되, 순차적으로 작성되어 있는 프로그램의 모두 모듈을 처리할 때 다른 부분은 실행하지 않는다. 프리 페이징은 처음에 발생하는 많은 페이지 부재를 방지하는 방법으로, 예상되는 모든 페이지를 사전에 한꺼번에 메모리 내로 가져온다.
요구 페이징의 장점을 열거하시오
:다중 프로그래밍의 정도를 증가시키고 액세스 하지 않은 페이지를 적재하지 않으므로, 다른 프로그램도 사용할수 있도록 메모리를 절약할 수 있다.
프로그램을 시작할 때 적재시간을 줄일 수 있다.
적은 수의 페이지를 읽기 때문에 초기 디스크 오버헤드가 적다.
페이지 부재를 디스크에서 페이지를 로드하는 데 사용할 수 있어 페이징 시스템보다 하드웨어 지원이 추가로 필요하지 않다.
적재된 페이지 중 하나를 수정할 때 까지 페이지들은 여러 프로그램이 공유 하므로 쓰기복사 기술로 더 많은 자원을 저장할 수 있다.
프로그램을 실행할 충분한 메모리가 없는 시스템에서도 대용량 프로그램을 실행 할 수 있으며, 프로그래머는 오버레이보다 쉽게 구현 할 수 있다.
페이지 부재란 무엇인지 설명하시오
:프로세스가 메인 메모리에 적재 되지 않은 페이지를 액세스 할때 하드웨어가 제기 하는 소프트웨어 트랩이다.
페이지 부재를 수행하는 여섯 단계를 열거하시오
:
프로세스 제어 블록에 있는 내부 테이블을 검사하여 프로세스가 메모리 액세스에 타당한지를 결정한다.
프로세스 참조가 무효화되었으면 프로세스가 중단되고, 유효한 페이지면 명령을 계속 처리하나 유효하지 않은 페이지면 페이지를 메모리에 가져와야한다.
메모리에서 빈 프레임 중 하나를 선택한다.
요구된 프레임에 요구된 페이지에 입출력하는 동안 프로세서는 다른 프로세스의 디스크 동작을 스케줄링 한다.
요구된 페이지가 메모리에 있다는것을 알리기 위해 페이지 테이블의 비타당 비트를 타당으로 변경한다.
주소 트랩으로 인터럽트 된 명령어를 다시 시작한다.
페이지 대치란 무엇인지 설명하시오
:페이지 부재가 발생하면, 메인 메모리에 있으면서 사용하지 않는 페이지를 없애 새로운 페이지로 바뀌는 작업이다.
스래싱이란 무엇인지 설명하시오
:페이지 교환이 계속 일어나는 현상이다.
작업 집합 모델의 장점을 설명하시오
:프로세스가 많이 참조하는 페이지 집합을 메모리 공간에 계속 상주시켜 빈번한 페이지 대치 현상을 줄인다.
단순 페이지 시스템을 다음 매개변수 관점에서 살펴보자
:
:논리적 주소의 크기가 16비트이고 페이지의 크기는 10바트 이므로 총 26비트이다.
②프레임에 몇 개의 바이트가 있는가?
:하나의 프레임은 하나의 페이지와 같으므로 10바이트이다.
③물리적 주소에서 프래임을 나타내는 비트는 몇개인가?
:물리적 주소에서 페이지 크기를 나누므로 32비트-10비트 즉 22비트이다.
④페이지 테이블에 있는 항목들은 몇개인가?
:논리적 주소에는 각 페이지에 해당하는 하나의 항목이 있다. 따라서 2의 16승만큼의 항목들이 있다.
⑤각 페이지 테이블 항목에 몇 개의 비트가 있는가?(단, 각 테이블 항목은 유효,무효 비트를 포함하고 있다고 가정한다.)
:페이지 테이블이 16비트이므로 15비트의 프레임이 있다.
프리 페이징을 사용하는 이유를 설명하시오
:입출력 인터럽트를 위해 연속된 페이지를 한 번에 메모리로 가져오기 때문에 입출력을 여러 번 수행하는 요구 페이지보다 더 성능이 좋기 때문이다.
페이지 크기를 결정하는 요소를 열거하시오
:페이지 테이블의 크기,프로세스 메모리의 크기, 내부 단편화,입출력 시간 최소화,페이지 부재
다음 페이지 참조열에서 ①~③의 대치 알고리즘에 페이지 부재가 몇개 일어나는가?(단, 페이지 프레임은 4개로 가정한다.)
①LRU:10회

②FIFO;9회

③Optimal:7회
2016년 10월 30일 일요일
의문문
의문사란 다들 알다시피 상대방에게 의중을 묻는 형의 문장형이다.
흔하게 해석할 수 있는 ~(입니)까? 이런 의미로 해석되는건 알것이라 믿는다.
쓰이는 법은 주어와 동사로 어순을 바꿔주고 종종 조동사 Do가 쓰이기도 한다.
이제 하나하나 살펴보도록 하자.
Be동사가 의문문으로 쓰이는 경우는
Be동사+주어+명사/형용사 패턴으로 쓰인다.
가장 흔히 예상할 수 있는 예문이
is she your sister?
Are you mad? 이다.
일반 동사를 의문문으로 쓰일때는 do동사가 필요하다.
Do동사+주어+동사의 표현으로 쓰인다.
일반동사는 다른 의문사와 달리 일반 동사가 앞으로 나오지 못하니 주의하자.
의문문에서 조동사가 쓰이는 경우도 있다.
I can read a book을 바꾸면 can i read a book. 으로 바뀐다는 것이다.
조동사 + 주어+ 동사로 조동사 의문문이 쓰이는데 다른 의문문과 달리 질문이 아니라
부탁이나 허락 등 특정 목적을 가지는 경우가 많다.
가장 크게 나눌수 있는 것은 could같은 부탁의 의미를 가지는 경우이고
would와 같이 권유를 의미하는 경우가 있으며 would like과 같은 격식표현을 지닌 권유가
지니는 경우가 있다.
의중을 묻는 것은 who,what,when,where,why,how 등이 있다.
의문사가 쓰이면 의문사+be동사+주어 혹은 의문사+조동사+주어+동사의 어순이 있다.
예문들을 보면서 확인해보도록하자.
What's your plan from now on?
What do you think about traveling abroad?
How do you like the movie?
Where can i find a restroom?
How can i contact you?
흔하게 해석할 수 있는 ~(입니)까? 이런 의미로 해석되는건 알것이라 믿는다.
쓰이는 법은 주어와 동사로 어순을 바꿔주고 종종 조동사 Do가 쓰이기도 한다.
이제 하나하나 살펴보도록 하자.
Be동사가 의문문으로 쓰이는 경우는
Be동사+주어+명사/형용사 패턴으로 쓰인다.
가장 흔히 예상할 수 있는 예문이
is she your sister?
Are you mad? 이다.
일반 동사를 의문문으로 쓰일때는 do동사가 필요하다.
Do동사+주어+동사의 표현으로 쓰인다.
일반동사는 다른 의문사와 달리 일반 동사가 앞으로 나오지 못하니 주의하자.
의문문에서 조동사가 쓰이는 경우도 있다.
I can read a book을 바꾸면 can i read a book. 으로 바뀐다는 것이다.
조동사 + 주어+ 동사로 조동사 의문문이 쓰이는데 다른 의문문과 달리 질문이 아니라
부탁이나 허락 등 특정 목적을 가지는 경우가 많다.
가장 크게 나눌수 있는 것은 could같은 부탁의 의미를 가지는 경우이고
would와 같이 권유를 의미하는 경우가 있으며 would like과 같은 격식표현을 지닌 권유가
지니는 경우가 있다.
의중을 묻는 것은 who,what,when,where,why,how 등이 있다.
의문사가 쓰이면 의문사+be동사+주어 혹은 의문사+조동사+주어+동사의 어순이 있다.
예문들을 보면서 확인해보도록하자.
What's your plan from now on?
What do you think about traveling abroad?
How do you like the movie?
Where can i find a restroom?
How can i contact you?
2016년 10월 28일 금요일
절-2
절은 명사역할을 할 수 있으므로 부사절을 할 수 있다.
일단 형용사절을 마무리하자. 관계부사절은 관계대명사절과 마찬가지로 명사 뒤에서 수식하는 역할을 한다. 관계부사는 각 역할에 따라 다르게 표현된다.
시간을 나타내면 when, 장소일때는 whrere, 방법은 why , 혹은 how로 표현한다.
또한 관계부사는 관계부사절 내에서 부사(전치사+명사)의 역할을 한다.
i remember the day when we first met.
This is the place where you can see the sea
I don't know the reason why she left me
Please tell me how you became so pretty.
그런데 이 when,where,how,why를 바꿀수 있는데 when은 on the day. where 는 at the place, why는 for the reason, how는 in the way로 바꾸는게 가능한다.
부사절은 때,이유 등을 나타내는 접속사가 쓰이며 위치는 문장앞이나 뒤 어디는 가능하다.
때를 표현하는 접속사로는 when, before,while등이 가능하다.
전에를 나타내는 before, 동안을 나타내는 while, ~까지인 (un)til, 이래로로 표현하는 since, ~하자 마자를 나타내는 as soon as, ~때 마다를 나타내는 everytime,whenever, 이유를 나타내는 because,as가 있다.
조건,양보의 부사절을 말해보자.
if,unless,once,as long as, in case.
if는 조건 부사로서 ~하면이라는 뜻이며 unless는 ~하지 않으면이란 뜻이다.
if we don't leave now
unless he talks to me first
once는 일단 ~하면이라는 말이다. as long as는 ~하기만 하면의 뜻이다.
once i start sneezing
as long as it's interesting
in case는 ~에 대비해서라는 뜻이다.
in case it rains
though,although,even though등은 역접의 뜻을 지닌다. 비록 ~이지만 혹은 ~하더라도 라는 뜻을 갖는다.
I admire her though i don't agree with her
Even though you're busy, don't forget to email me often
일단 형용사절을 마무리하자. 관계부사절은 관계대명사절과 마찬가지로 명사 뒤에서 수식하는 역할을 한다. 관계부사는 각 역할에 따라 다르게 표현된다.
시간을 나타내면 when, 장소일때는 whrere, 방법은 why , 혹은 how로 표현한다.
또한 관계부사는 관계부사절 내에서 부사(전치사+명사)의 역할을 한다.
i remember the day when we first met.
This is the place where you can see the sea
I don't know the reason why she left me
Please tell me how you became so pretty.
그런데 이 when,where,how,why를 바꿀수 있는데 when은 on the day. where 는 at the place, why는 for the reason, how는 in the way로 바꾸는게 가능한다.
부사절은 때,이유 등을 나타내는 접속사가 쓰이며 위치는 문장앞이나 뒤 어디는 가능하다.
때를 표현하는 접속사로는 when, before,while등이 가능하다.
전에를 나타내는 before, 동안을 나타내는 while, ~까지인 (un)til, 이래로로 표현하는 since, ~하자 마자를 나타내는 as soon as, ~때 마다를 나타내는 everytime,whenever, 이유를 나타내는 because,as가 있다.
조건,양보의 부사절을 말해보자.
if,unless,once,as long as, in case.
if는 조건 부사로서 ~하면이라는 뜻이며 unless는 ~하지 않으면이란 뜻이다.
if we don't leave now
unless he talks to me first
once는 일단 ~하면이라는 말이다. as long as는 ~하기만 하면의 뜻이다.
once i start sneezing
as long as it's interesting
in case는 ~에 대비해서라는 뜻이다.
in case it rains
though,although,even though등은 역접의 뜻을 지닌다. 비록 ~이지만 혹은 ~하더라도 라는 뜻을 갖는다.
I admire her though i don't agree with her
Even though you're busy, don't forget to email me often
2016년 10월 25일 화요일
7강 os
논리적 주소와 물리적 주소 차이를 설명하시오
:논리적 주소란 가상의 주소로 cpu가 생성한 주소를 말한다. 목적 코드가 저장된 공간과 프로그램에서 사용하는 자료구조 등이 이에 해당하며 물리적 주소는 논리적 주소에 대응하여 적재하는 주소로, 메모리 팁이나 디스크 공간에서 생성된다.
프레임 32개로 구성된 실제 물리적 주소 공간으로 매핑되는 1024byte의 페이지 8개인 논리적 주소 공간을 생각해 보자
:
1) 논리적 주소에 몇 개의 비트가 있는가?
1024가 2의 10승이고 8이 2의 승이므로 10+3으로 2의 13승이되니 13비트이다.
2) 물리적 주소에 몇 개의 비트가 있는가?
32가 2의 5승이고 1024가 2의 10승이므로 2의 15승 15비트이다.
다음 할당 알고리즘을 설명하시오
:
1)최초 적합
:프로세스를 사용가능 공간 중 충분히 큰 첫번째 공간에 할당하는 방법으로 사용가능 공간의 리스트 맨 랖이나 이전의 최초 적합 검색이 끝났던 곳에서 시작하면 충분히 큰 사용공간을 찾을수 있다.
2)최적 적합
: 프로세스를 충분히 큰 사용 가능 공간 중에서 들어갈 수 있는 가장 작은 공간에 할 당 한다. 사용 가능 공간을 계속 정렬하는 과정이 필요하므로 시간이 많이 소모되 비효율적일 수 있지만 사용가능 공간의 이용룰은 향상된다.
3)최악 적합
:프로세스를 가장 큰 사용공간에 할당된다. 최적 적합과 같이 공간을 계속 정렬해야하므로 시간이 걸리나 가장 큰 공간에 할당하기 때문에 가장 작은 또 다른 사용 가능 공산을 만들 필요가 없어 메모리 활용면에서 더 유용하다.
4)100KB,500kb,200kb,300kb,600kb 순으로 기억장치가 분할 되었을떄 1~3개의 알고리즘은 프로세스 212kb,417kb,112kb,426kb를 어떤 순서로 할당 하는가? 어느 알고리즘이 기억장치를 가장 적정하게 사용하는가?
:최초적합을 사용한다면 500kb->600kb->500kb그리고 426kb는 다른 프로세스가 작업을 끝낼때 까지 대기한다.
최적 적합은 300kb-> 500kb->200kb->600kb 순으로 사용이 된다.
최악 적합은 600kb->500kb->300kb 그리고 426kb는 다른 프로세스가 작업을 끝낼때까지 대기해야한다.
내부 단편화와 외부 단편화의 차이를 설명하시오
:내부 단편화는 분할된 메모리속에 프로세스가 할당 된후 남는 메모리를 말하며 외부 단편화는 분할된 메모리가 프로세스보다 작아서 할당을 못받는 경우 이를 외부 단편화라 한다.
왼쪽 세그먼트 테이블을 참고하여 오른쪽 1~6의 논리적 주소에서 물리적 주소를 구하시오.
:
 1)0,430 :649
1)0,430 :649
2)1,10 :2310
3)1,11:2311
4)2,500 :590
5)3,400 :1727
6)4,112 :2064
세그먼트 하나가 다른프로세스 2개의 주소공간에 속할 수 있는 방법을 설명하시오
:세그먼트 공유를 하면 되는데 공유한다고 선언만 하면 된다. 세그먼트 테이블에 있는 항목을 동일한 메모리 주소를 지정하면 공유가 가능하다.
페이지 테이블을 메모리에 저장한 페이징 시스템이 있다. 다음 질문에 답하시오
:1)메모리 참조가 200나노초 걸렸다면, 페이지로 된 기억장치의 참조는 얼마나 걸리는가?
:메모리 참조가 200나노초 그리고 페이지로 기억창지 참조 시간 200초로 총 400초가 걸린다.
2)연관 레지스터를 추가하여 모든 페이지 테이블 참조의 75%를 연관 레지스터에서 찾는다면, 실제 메모리 접근시간은 얼마나 되는가?(단, 연관 레지스터에서 어떤 페이지 테이블 항목을 찾을때 해당 항목이 그곳에 있는다면 시간은 걸리지 않는다고 가정한다.)
:0.75*200+0.25*400으로 150+100인 250초 걸린다.
페이지 테이블에서 항목 2개가 메모리의 동일한 페이지 프레임을 가리킨다면 그 결과는 어떻게 될까? 많은 양의 메모리를 한 장소에서 다른 장소로 복사할 때 이것을 사용하여 어떻게 필요한 시간의 양을 감소시킬수 있는가? 한 페이지를 다른 페이지로 업데이트했을 때 어떤 효과가 있는가?
: 2개의 항목들이 메오리에서 동일한 페이지로 나타나게 하면 사용자들은 코드와 데이터를 공유 할 수 있다. 많은 양의 메모리를 복사한다면 서로다른 테이블들을 동일한 메모리 할당을 나타내게 하므로 시간의 양을 감소 시킬 수 있다. 한페이지를 다른 페이지로 업데이트 했을땐 그 코드를 사용 할 수 있는 모든 상용자가 그것을 변경 할 수 있고 다른 사용자들이 복사 할 수 있다.
바인딩을 설명 하시오
:하나의 프로세스에 논리적 주소와 물리적 주소를 연결 시켜주는 작업을 의미한다.
중첩(오버레이)의 개념과 단점을 설명하시오
:운영체제 영역과 메모리 일부에는 프로그램에 꼭 필요한 명령어와 데이터만 저장하고 나머지는 필요할때 호출하여 적재하는 방법이다. 무척이나 효율적인 방법이긴 하지만 프로그램의 크기가 거대해져 전체 자료구조를 이해하기 어려워 항상 사용은 못하므로 제한된 하드웨어에서만 사용한다.
동적 적재의 개념과 장점을 설명하시오
:바인딩을 최대한 늦춰 실행 직전에 주소를 확정하여 메모리를 효율적으로 운영하는 방법을 말한다. 사용하지 않을 루틴을 메모리에 적재하지 않으므로 메모리를 효율적으로 사용할 수 있으며 프로그램 전체 양이 많을 떄 유용하다.
재할당 레지스터를 설명하시오
: 수행중인 프로그램을 다른 곳으로 옮기게 해줘 프로그램이 계속 실행되게 해준다. 이렇게 하면 프로그래머는 마치 0번지에서 시작 하는 것처럼 프로그램을 작성 할 수있다.
고정분할 영역을 만드는 방법을 열거하시오
:기준 레지스터와 한계 레지스터를 사용하는 방법과 현재 실행 중인 위.아래 바운드 레지스터를 사용하는 방법이다.
세그먼트를 설명하시오
:가상 기억장치에 있어서 가장 어드레스 구조를 실현하기 위해 운영체제에 의해 어떤 바이트 수 단위로 분할되는 가상 기억 영역을 말한다.
페이지크기가 4kb이고 메모리 크기가 256kb인 메모리 페이징 시스템이 있다고 가정하여 다음 질문에 답하시오
1) 페이지 프레임 수는?
:256의 메모리가 4kb의 크기를 가지니 총 64개이다.
2)이 메모리 주소를 해결하는 데 필요한 비트는?
:4kb는 2의 12승이고 페이지 프레임은 256kb로 2의 6승이다. 따라서 18비트이다.
3)페이지 번호에 사용하는 비트 페이지 오프셋에 사용하는 비트는?
:페이지 번호는 6비트이고 페이지오프셋은 12비트이다.
크기가 212바이트인 동일한 분할(영역)과 232바이트의 메인 메모리를 갖는 고정 분할 방법을 사용하는 시스템이 있다고 가정하자. 프로세스 테이블은 각 상주 프로세스의 분할 포인터를 유지한다. 프로세스 테이블의 포인터에 필요한 비트는?
:프로세스 테이블 포인터는 시스템의 각 분할을 가리킬수 있어야한다. 따라서 메인메모리 크기를 분할 크키로 나누어 필요 비트를 나타낼 수 있다. 즉 2의 20승으로 20비트이다.
페이지 크기가 1KB라고 가정하면, 다음 주소 참조에서 페이지 번호와 어프셋은?
:

페이징 시스템에서 프로세스는 쇼유하지 않는(적재되지 않는) 메모리에 액세스 할 수 없다. 다음 질문에 답하시오
:
1) 프로세스가 소유하지 않는(적재되지 않는)메모리에 엑세스 할 수 없는 이유는?
:페이징 시스템의 주소는 논리적 페이지 번호와 오프셋이다. 이 논리적 페이지는 물리적 페이지를 기반으로 검색하기 때문에 프로세스에 할당된 물리페이지에 엑세스하도록 프로세스를 제한할 수 있다. 따라서 프로세스는 그 페이지가 페이지 테이블에 없기 때문에 페이지를 참조할 수 없다.
2)운영체제가 다른 메모리에 엑세스 할 수 있을까? 그리고 운영체제가 다른 메모리에 엑세스 할 수 있게 해야하는가 , 아니면 하지 않아도 되는가?
:이러한 엑세스를 허용하기 위해, 운영체제는 적제되지 않은 메모리에 대한 항목은 프로세스의 페이지 테이블에 단순하게 추가되도록 할 필요가 있다. 두 개 이상의 프로세스가 다른 논리 주소라도 동일한 물리적 주소로 읽고 작성할 때 유용하다.
페이징 시스템에서 페이지 테이블이 어떤 기능을 하는지 설명하시오
:페이지의 논리적 주소인 페이지 번호와 이에 대응하는 물리적 주소인 페이지 프레임 주소를 포함하며 별도의 레지스터로 구성하거나 메인 메모리에 배치하기도 한다.
컴파일러에서는 함수 호출이나 순환의 시작부분으로 점프하는 코드와 데이터를 참조하는 주소를 생성해야한다. 메모리 시스템에서 이 주소는 물리적인 주소인가, 아니면 논리적 주소인가.
: 논리적 주소이다. 함수 호출과 순환 부분 그리고 데이터를 참조하는 주소를 생성하려면 페이지 테이블을 참조 해야하므로 물리적 주소를 참조되야한다. 따라서 논리적 주소이다.
:논리적 주소란 가상의 주소로 cpu가 생성한 주소를 말한다. 목적 코드가 저장된 공간과 프로그램에서 사용하는 자료구조 등이 이에 해당하며 물리적 주소는 논리적 주소에 대응하여 적재하는 주소로, 메모리 팁이나 디스크 공간에서 생성된다.
프레임 32개로 구성된 실제 물리적 주소 공간으로 매핑되는 1024byte의 페이지 8개인 논리적 주소 공간을 생각해 보자
:
1) 논리적 주소에 몇 개의 비트가 있는가?
1024가 2의 10승이고 8이 2의 승이므로 10+3으로 2의 13승이되니 13비트이다.
2) 물리적 주소에 몇 개의 비트가 있는가?
32가 2의 5승이고 1024가 2의 10승이므로 2의 15승 15비트이다.
다음 할당 알고리즘을 설명하시오
:
1)최초 적합
:프로세스를 사용가능 공간 중 충분히 큰 첫번째 공간에 할당하는 방법으로 사용가능 공간의 리스트 맨 랖이나 이전의 최초 적합 검색이 끝났던 곳에서 시작하면 충분히 큰 사용공간을 찾을수 있다.
2)최적 적합
: 프로세스를 충분히 큰 사용 가능 공간 중에서 들어갈 수 있는 가장 작은 공간에 할 당 한다. 사용 가능 공간을 계속 정렬하는 과정이 필요하므로 시간이 많이 소모되 비효율적일 수 있지만 사용가능 공간의 이용룰은 향상된다.
3)최악 적합
:프로세스를 가장 큰 사용공간에 할당된다. 최적 적합과 같이 공간을 계속 정렬해야하므로 시간이 걸리나 가장 큰 공간에 할당하기 때문에 가장 작은 또 다른 사용 가능 공산을 만들 필요가 없어 메모리 활용면에서 더 유용하다.
4)100KB,500kb,200kb,300kb,600kb 순으로 기억장치가 분할 되었을떄 1~3개의 알고리즘은 프로세스 212kb,417kb,112kb,426kb를 어떤 순서로 할당 하는가? 어느 알고리즘이 기억장치를 가장 적정하게 사용하는가?
:최초적합을 사용한다면 500kb->600kb->500kb그리고 426kb는 다른 프로세스가 작업을 끝낼때 까지 대기한다.
최적 적합은 300kb-> 500kb->200kb->600kb 순으로 사용이 된다.
최악 적합은 600kb->500kb->300kb 그리고 426kb는 다른 프로세스가 작업을 끝낼때까지 대기해야한다.
내부 단편화와 외부 단편화의 차이를 설명하시오
:내부 단편화는 분할된 메모리속에 프로세스가 할당 된후 남는 메모리를 말하며 외부 단편화는 분할된 메모리가 프로세스보다 작아서 할당을 못받는 경우 이를 외부 단편화라 한다.
왼쪽 세그먼트 테이블을 참고하여 오른쪽 1~6의 논리적 주소에서 물리적 주소를 구하시오.
:

2)1,10 :2310
3)1,11:2311
4)2,500 :590
5)3,400 :1727
6)4,112 :2064
세그먼트 하나가 다른프로세스 2개의 주소공간에 속할 수 있는 방법을 설명하시오
:세그먼트 공유를 하면 되는데 공유한다고 선언만 하면 된다. 세그먼트 테이블에 있는 항목을 동일한 메모리 주소를 지정하면 공유가 가능하다.
페이지 테이블을 메모리에 저장한 페이징 시스템이 있다. 다음 질문에 답하시오
:1)메모리 참조가 200나노초 걸렸다면, 페이지로 된 기억장치의 참조는 얼마나 걸리는가?
:메모리 참조가 200나노초 그리고 페이지로 기억창지 참조 시간 200초로 총 400초가 걸린다.
2)연관 레지스터를 추가하여 모든 페이지 테이블 참조의 75%를 연관 레지스터에서 찾는다면, 실제 메모리 접근시간은 얼마나 되는가?(단, 연관 레지스터에서 어떤 페이지 테이블 항목을 찾을때 해당 항목이 그곳에 있는다면 시간은 걸리지 않는다고 가정한다.)
:0.75*200+0.25*400으로 150+100인 250초 걸린다.
페이지 테이블에서 항목 2개가 메모리의 동일한 페이지 프레임을 가리킨다면 그 결과는 어떻게 될까? 많은 양의 메모리를 한 장소에서 다른 장소로 복사할 때 이것을 사용하여 어떻게 필요한 시간의 양을 감소시킬수 있는가? 한 페이지를 다른 페이지로 업데이트했을 때 어떤 효과가 있는가?
: 2개의 항목들이 메오리에서 동일한 페이지로 나타나게 하면 사용자들은 코드와 데이터를 공유 할 수 있다. 많은 양의 메모리를 복사한다면 서로다른 테이블들을 동일한 메모리 할당을 나타내게 하므로 시간의 양을 감소 시킬 수 있다. 한페이지를 다른 페이지로 업데이트 했을땐 그 코드를 사용 할 수 있는 모든 상용자가 그것을 변경 할 수 있고 다른 사용자들이 복사 할 수 있다.
바인딩을 설명 하시오
:하나의 프로세스에 논리적 주소와 물리적 주소를 연결 시켜주는 작업을 의미한다.
중첩(오버레이)의 개념과 단점을 설명하시오
:운영체제 영역과 메모리 일부에는 프로그램에 꼭 필요한 명령어와 데이터만 저장하고 나머지는 필요할때 호출하여 적재하는 방법이다. 무척이나 효율적인 방법이긴 하지만 프로그램의 크기가 거대해져 전체 자료구조를 이해하기 어려워 항상 사용은 못하므로 제한된 하드웨어에서만 사용한다.
동적 적재의 개념과 장점을 설명하시오
:바인딩을 최대한 늦춰 실행 직전에 주소를 확정하여 메모리를 효율적으로 운영하는 방법을 말한다. 사용하지 않을 루틴을 메모리에 적재하지 않으므로 메모리를 효율적으로 사용할 수 있으며 프로그램 전체 양이 많을 떄 유용하다.
재할당 레지스터를 설명하시오
: 수행중인 프로그램을 다른 곳으로 옮기게 해줘 프로그램이 계속 실행되게 해준다. 이렇게 하면 프로그래머는 마치 0번지에서 시작 하는 것처럼 프로그램을 작성 할 수있다.
고정분할 영역을 만드는 방법을 열거하시오
:기준 레지스터와 한계 레지스터를 사용하는 방법과 현재 실행 중인 위.아래 바운드 레지스터를 사용하는 방법이다.
세그먼트를 설명하시오
:가상 기억장치에 있어서 가장 어드레스 구조를 실현하기 위해 운영체제에 의해 어떤 바이트 수 단위로 분할되는 가상 기억 영역을 말한다.
페이지크기가 4kb이고 메모리 크기가 256kb인 메모리 페이징 시스템이 있다고 가정하여 다음 질문에 답하시오
1) 페이지 프레임 수는?
:256의 메모리가 4kb의 크기를 가지니 총 64개이다.
2)이 메모리 주소를 해결하는 데 필요한 비트는?
:4kb는 2의 12승이고 페이지 프레임은 256kb로 2의 6승이다. 따라서 18비트이다.
3)페이지 번호에 사용하는 비트 페이지 오프셋에 사용하는 비트는?
:페이지 번호는 6비트이고 페이지오프셋은 12비트이다.
크기가 212바이트인 동일한 분할(영역)과 232바이트의 메인 메모리를 갖는 고정 분할 방법을 사용하는 시스템이 있다고 가정하자. 프로세스 테이블은 각 상주 프로세스의 분할 포인터를 유지한다. 프로세스 테이블의 포인터에 필요한 비트는?
:프로세스 테이블 포인터는 시스템의 각 분할을 가리킬수 있어야한다. 따라서 메인메모리 크기를 분할 크키로 나누어 필요 비트를 나타낼 수 있다. 즉 2의 20승으로 20비트이다.
페이지 크기가 1KB라고 가정하면, 다음 주소 참조에서 페이지 번호와 어프셋은?
:

페이징 시스템에서 프로세스는 쇼유하지 않는(적재되지 않는) 메모리에 액세스 할 수 없다. 다음 질문에 답하시오
:
1) 프로세스가 소유하지 않는(적재되지 않는)메모리에 엑세스 할 수 없는 이유는?
:페이징 시스템의 주소는 논리적 페이지 번호와 오프셋이다. 이 논리적 페이지는 물리적 페이지를 기반으로 검색하기 때문에 프로세스에 할당된 물리페이지에 엑세스하도록 프로세스를 제한할 수 있다. 따라서 프로세스는 그 페이지가 페이지 테이블에 없기 때문에 페이지를 참조할 수 없다.
2)운영체제가 다른 메모리에 엑세스 할 수 있을까? 그리고 운영체제가 다른 메모리에 엑세스 할 수 있게 해야하는가 , 아니면 하지 않아도 되는가?
:이러한 엑세스를 허용하기 위해, 운영체제는 적제되지 않은 메모리에 대한 항목은 프로세스의 페이지 테이블에 단순하게 추가되도록 할 필요가 있다. 두 개 이상의 프로세스가 다른 논리 주소라도 동일한 물리적 주소로 읽고 작성할 때 유용하다.
페이징 시스템에서 페이지 테이블이 어떤 기능을 하는지 설명하시오
:페이지의 논리적 주소인 페이지 번호와 이에 대응하는 물리적 주소인 페이지 프레임 주소를 포함하며 별도의 레지스터로 구성하거나 메인 메모리에 배치하기도 한다.
컴파일러에서는 함수 호출이나 순환의 시작부분으로 점프하는 코드와 데이터를 참조하는 주소를 생성해야한다. 메모리 시스템에서 이 주소는 물리적인 주소인가, 아니면 논리적 주소인가.
: 논리적 주소이다. 함수 호출과 순환 부분 그리고 데이터를 참조하는 주소를 생성하려면 페이지 테이블을 참조 해야하므로 물리적 주소를 참조되야한다. 따라서 논리적 주소이다.
절-1
절이란 둘 이상의 문장을 하나의 문장으로 구성되어 있는 것을 말한다. 이것을 만드는 것이 바로 접속사다. 접속사에서는 가장 유명한것은 That과 what이다. 지금은 언급 안하겠지만 나중에 이 두 접속사에 대해 말하겠다.
우선적으로 명사절에 대해 말해보도록 하겠다. 아무리 절이라도 명사이기 때문에 명사의 속성을 유지한다. 때문에 목적어,주어,형용사,부사로 쓰일 수 있다.그럼 이제 하나씩 살펴보도록하자.
목적어 절은 말 그대로 목적어로써 사용이 가능하다. 이 절에서 사용되는 접속사는 that, if, 의문사 등이 가능하다. 접속사가 이끄는 절은 목적어로서 큰 절에안겨있듯이 보인다.
I believe that she will win
이 문장에서 that절은 전체 문장 속에 포함되며 이 문장의 목적어 역할을 하고 있다.
that은 특별한 의미는 없고 '~(하)는 것' 혹은 그것은 의 의미를 갖는다. 생략이 가능해 생략시 문장의 구조를 잘 파악해야 한다.
I know you are French. 여기서 that을 생략하여 ~라는 것의 의미를 갖는다.
I don't know if the rumor is true 여기서 if는 뒷 문장과 연결 시켜주는 접속사로서 역할을 한다. 이때 if는 만약의 조건이 아니라 ~인지라는 의미로 조건아닌 조건의 의미를 갖는 것이다.
의문사가 명사절을 이끌때도 있다.
I don't know why she was so angry
의미는 똑같이 의문문으로 해석하면 된다.
주어절로 쓰이는 방법을 말하겠다.
여기서 한가지를 알아야 하는것은 기본적으로 영어는 가벼운 정보가 무거운 정보보다 먼저 나오기 때문에 주어인 명사절은 주어위치가 아닌 목적어 뒤로 오는 경우가 상당하다.
문장의 주어로 명사절인 that과 if절이 쓰이는데 막상 만들어보면 앞머리가 무거워진다. 이때 가주어인 It을 주어 자리에 두도록 만든다.
It's necessary that you attend the morning
Is it okay if I drop in at 2:30?
여기서 it은 가주어로서 의미를 특별히 갖지 않으며 that문장과 if문장은 주어역할을 하는 절이다.
이때 목적어가 감정이나 형용사일 경우엔 의미가 조금 달라진다. 명사절의 의미는 ~하다니로 해석하면 자연스럽다.
It's a pity that he died so young
여기서 that은 ~하게 되니로 해석하면 좋다. 물론 꼭 그럴 필요는 없다.
형용사절에서 주격대명사절을 알아보자.
관계대명사절은 명사를 뒤에서 수식하는 형용사 역할을 하는 절이다.
이 대명사 who,which,that등이 관계대명사절 전체를 이끈다.
우리말에는 관계대명사에 해당하는 말이 따로 없지만 뭐든 꾸미는 말이 앞으로 나오지만 영어에서는 마치 소시지처럼 정보가 차례로 나열되어 있다.
She likes a man who is good at singing.
관계대명사에서 한가지 봐야 할 것은 수식하는 대상이 사람이면 that 또는 who, 사물이면 which와 that으로 사용한다. 또한 목적이 무엇이냐에 따라 주격과 목적격으로 구분된다.
우선적으로 명사절에 대해 말해보도록 하겠다. 아무리 절이라도 명사이기 때문에 명사의 속성을 유지한다. 때문에 목적어,주어,형용사,부사로 쓰일 수 있다.그럼 이제 하나씩 살펴보도록하자.
목적어 절은 말 그대로 목적어로써 사용이 가능하다. 이 절에서 사용되는 접속사는 that, if, 의문사 등이 가능하다. 접속사가 이끄는 절은 목적어로서 큰 절에안겨있듯이 보인다.
I believe that she will win
이 문장에서 that절은 전체 문장 속에 포함되며 이 문장의 목적어 역할을 하고 있다.
that은 특별한 의미는 없고 '~(하)는 것' 혹은 그것은 의 의미를 갖는다. 생략이 가능해 생략시 문장의 구조를 잘 파악해야 한다.
I know you are French. 여기서 that을 생략하여 ~라는 것의 의미를 갖는다.
I don't know if the rumor is true 여기서 if는 뒷 문장과 연결 시켜주는 접속사로서 역할을 한다. 이때 if는 만약의 조건이 아니라 ~인지라는 의미로 조건아닌 조건의 의미를 갖는 것이다.
의문사가 명사절을 이끌때도 있다.
I don't know why she was so angry
의미는 똑같이 의문문으로 해석하면 된다.
주어절로 쓰이는 방법을 말하겠다.
여기서 한가지를 알아야 하는것은 기본적으로 영어는 가벼운 정보가 무거운 정보보다 먼저 나오기 때문에 주어인 명사절은 주어위치가 아닌 목적어 뒤로 오는 경우가 상당하다.
문장의 주어로 명사절인 that과 if절이 쓰이는데 막상 만들어보면 앞머리가 무거워진다. 이때 가주어인 It을 주어 자리에 두도록 만든다.
It's necessary that you attend the morning
Is it okay if I drop in at 2:30?
여기서 it은 가주어로서 의미를 특별히 갖지 않으며 that문장과 if문장은 주어역할을 하는 절이다.
이때 목적어가 감정이나 형용사일 경우엔 의미가 조금 달라진다. 명사절의 의미는 ~하다니로 해석하면 자연스럽다.
It's a pity that he died so young
여기서 that은 ~하게 되니로 해석하면 좋다. 물론 꼭 그럴 필요는 없다.
형용사절에서 주격대명사절을 알아보자.
관계대명사절은 명사를 뒤에서 수식하는 형용사 역할을 하는 절이다.
이 대명사 who,which,that등이 관계대명사절 전체를 이끈다.
우리말에는 관계대명사에 해당하는 말이 따로 없지만 뭐든 꾸미는 말이 앞으로 나오지만 영어에서는 마치 소시지처럼 정보가 차례로 나열되어 있다.
She likes a man who is good at singing.
관계대명사에서 한가지 봐야 할 것은 수식하는 대상이 사람이면 that 또는 who, 사물이면 which와 that으로 사용한다. 또한 목적이 무엇이냐에 따라 주격과 목적격으로 구분된다.
2016년 10월 23일 일요일
전치사구의 수식과 부사 역할
전치사란 명사 앞에 위치하는 품사로 on,at,in,for,from,등이 있다. 하나의 전치사는 다양한 의미가 있어 하나만 외우기란 힘들어 이미징해서 외우는 방식이 좋다. 여기서는 전치사 구를 설명하기 때문에 지금 말하지는 않겠지만 심도있게 생각하도록 하는게 좋을거다.
전치사구는 전치사+명사로 이떄 명사는 전치사의 목적어로 쓰인다.
예를 들자면
in front of me, with a gun, next to the window 등 전치사와 명사로 되어있다.
여기서 중요한 건 전치사의 의미를 알아야 한다는 것이다.
to부정사는 여러모로 쓰임세가 많다는건 앞에서 소개를 해서 잘 알것이다. 부사 역할은 대체로 어떤것을 하기 위해서의 목적의 의미로 많이 쓰인다. 가장 많이 쓰이다 보니 웃기게도
I'm pleased to see you again
이 문장을 저렇게 해석하면 너를 다시 보기위해 기쁘다. 이렇게 해석하게 된다.
이 문장은 ~하니로 해석을 해야한다.
결론적으로 to부정사는 '~하기 위해'의 목적의 의미와 '~해서' 혹은 ' ~때문에' 결과의 의미를 갖게 되니 잘 알아두자.
전치사구의 부사는 주로 시간 및 방법 그리고 장소 등 다양한 의미를 지닌다.
이건 설명할게 없고 예문으로 보면 알것이다.
I wake up at dawn.
They met on a blind date for the first time
There's a pharmacy right next to the hospital
l'm going in the same direction
I don't want to eat by myself
My daughter passed the exam with difficulty
각 2 문장씩 같은 의미를 가지는 전치사구이다. 첫번째와 두번째는 시간을 나타내는 의미이며 3,4번째는 장소를 의미한다, 마지막 2문장은 방법을 나타낸다. 각 전치사마다 의미가 담겨있지만 모든 것이 정해져있지 않으므로 한정 짓는 것은 금물이다.
전치사구는 전치사+명사로 이떄 명사는 전치사의 목적어로 쓰인다.
예를 들자면
in front of me, with a gun, next to the window 등 전치사와 명사로 되어있다.
여기서 중요한 건 전치사의 의미를 알아야 한다는 것이다.
to부정사는 여러모로 쓰임세가 많다는건 앞에서 소개를 해서 잘 알것이다. 부사 역할은 대체로 어떤것을 하기 위해서의 목적의 의미로 많이 쓰인다. 가장 많이 쓰이다 보니 웃기게도
I'm pleased to see you again
이 문장을 저렇게 해석하면 너를 다시 보기위해 기쁘다. 이렇게 해석하게 된다.
이 문장은 ~하니로 해석을 해야한다.
결론적으로 to부정사는 '~하기 위해'의 목적의 의미와 '~해서' 혹은 ' ~때문에' 결과의 의미를 갖게 되니 잘 알아두자.
전치사구의 부사는 주로 시간 및 방법 그리고 장소 등 다양한 의미를 지닌다.
이건 설명할게 없고 예문으로 보면 알것이다.
I wake up at dawn.
They met on a blind date for the first time
There's a pharmacy right next to the hospital
l'm going in the same direction
I don't want to eat by myself
My daughter passed the exam with difficulty
각 2 문장씩 같은 의미를 가지는 전치사구이다. 첫번째와 두번째는 시간을 나타내는 의미이며 3,4번째는 장소를 의미한다, 마지막 2문장은 방법을 나타낸다. 각 전치사마다 의미가 담겨있지만 모든 것이 정해져있지 않으므로 한정 짓는 것은 금물이다.
6화 os
단기 스케줄링, 중기 스케줄링, 장기 스케줄링의 차이를 기술하시오.
: 단기 스케줄링은 프로세서 스케줄러라고 부르며 메인 메모리의 준비상태에 있는 작 업 중에서 실행할 작업을 선택하고 프로세서를 배당하는 일을 한다.
중기 스케줄링은 현재 생성되어 있는 프로세스 중에 비효율적으로 시스템의 자원을 낭비 하고 있는 프로세스가 있을 경우 보조기억장치로 추방하는 스케줄링이다.
장기 스케줄링은 작업 스케줄러라고 부르기도 하며 어떤 작업이 시스템에 들어와서 스케 줄링 원칙에 따라 디스크 내의 어떤 작업을 어떤 순서로 메모리에 가져와서 처리할 것인 가를 결정하는 프로그램
선점 스케줄링과 비선점 스케줄링의 차이점을 정의하시오. 엄격한 비선점식 스케줄링을 사용하지 않는 이유도 설명하시오.
:선점 스케줄링은 실행중인 프로세스를 중간에 중지하고 다른 프로세스를 실행할수 있으며 비선점 스케줄링 실행중인 프로세스를 중지 불가능하다 .
62. 다음 프로세스들이 시간 0에 P1, P2, P3, P4, P5 순으로 도착한다고 가정하여 다음 질문에 답하시오.
:

선입선처리, 최소작업 우선, 비선점 우선순위, 순환 할당(할당량=1)을 이용하여 이를 프로 세스들의 실행을 설명하는 간트 차트로 그리시오.
[선입선처리]

[최소작업 우선]

[선점 우선순위]

[순환 할당]

[HRN]

각 스케줄링 알고리즘에 대한 반환시간은?
선입선처리 : 38.2
선점 최소작업 우선 : 24
선점 우선순위 : 33
순환 할당 : 34.8
HRN : 25.2
각 스케줄링 알고리즘에 대한 대기시간은?
선입선처리 : 26
선점 최소작업 우선 : 11.8
선점 우선순위 : 20.8
순환 할당 : 22.6
HRN : 12.8
어떤 스케줄링이 모든 프로세스에서 최소의 평균 대기시간을 갖는가?
:평균 대기시간 11.8로 선점 최소작업 우선 방식의 평균대기시간이 가장 작다.
스케줄링의 목적을 기술하시오.
:자원 할당의 공정성 보장하며 단위 시간당 처리량 최대화한다. 또한 오버헤드를 최소화하고 자원 사용의 균형 유지 등 최대한 효율적으로 결과를 내기 위함이다.
스케줄링의 성능 기준 요소를 기술하시오.
: 사용률과 처리율, 최대화 반환시간 최소화, 대기시간 최소화, 반응 시간 최소화
다단계 피드백 큐 스케줄링 알고리즘과 전면 작업에는 라운드 로빈(순환 할당) 스케줄링 을 사용하고, 후면 작업에는 선점 우선순위 알고리즘을 사용하는 다단계 큐(전면-후면) 프로 세서 스케줄링 알고리즘의 차이를 설명하시오.
:다단계 귀환 스케줄링은 작업이 큐 사이를 이동 가능하며 서로 다른 프로세서 버스트 특성에 따라 분리 구분한다. 작업이 요구하는 프로세서 시간이 너무 크면 낮은 단계 큐로 이동 하고 입출력 중심작업과 전면 작업을 높은 우선순위 큐로 이동 하는 반면 낮은 우선순위 큐에서 오래 기다린 작업은 높은 우선순위 큐로 이동한다.
다단계 큐는 작업이 한 큐에만 고정되어 실행되며 큐 사이에 옮겨지지 않는다. 전면 작업과 후면 작업의 성질을 바꿀 수 없다. 그리고 스케줄링 부담이 적은 장점이 있으나 융통성이 적다
: 단기 스케줄링은 프로세서 스케줄러라고 부르며 메인 메모리의 준비상태에 있는 작 업 중에서 실행할 작업을 선택하고 프로세서를 배당하는 일을 한다.
중기 스케줄링은 현재 생성되어 있는 프로세스 중에 비효율적으로 시스템의 자원을 낭비 하고 있는 프로세스가 있을 경우 보조기억장치로 추방하는 스케줄링이다.
장기 스케줄링은 작업 스케줄러라고 부르기도 하며 어떤 작업이 시스템에 들어와서 스케 줄링 원칙에 따라 디스크 내의 어떤 작업을 어떤 순서로 메모리에 가져와서 처리할 것인 가를 결정하는 프로그램
선점 스케줄링과 비선점 스케줄링의 차이점을 정의하시오. 엄격한 비선점식 스케줄링을 사용하지 않는 이유도 설명하시오.
:선점 스케줄링은 실행중인 프로세스를 중간에 중지하고 다른 프로세스를 실행할수 있으며 비선점 스케줄링 실행중인 프로세스를 중지 불가능하다 .
62. 다음 프로세스들이 시간 0에 P1, P2, P3, P4, P5 순으로 도착한다고 가정하여 다음 질문에 답하시오.
:

선입선처리, 최소작업 우선, 비선점 우선순위, 순환 할당(할당량=1)을 이용하여 이를 프로 세스들의 실행을 설명하는 간트 차트로 그리시오.
[선입선처리]

[최소작업 우선]

[선점 우선순위]

[순환 할당]

[HRN]

각 스케줄링 알고리즘에 대한 반환시간은?
선입선처리 : 38.2
선점 최소작업 우선 : 24
선점 우선순위 : 33
순환 할당 : 34.8
HRN : 25.2
각 스케줄링 알고리즘에 대한 대기시간은?
선입선처리 : 26
선점 최소작업 우선 : 11.8
선점 우선순위 : 20.8
순환 할당 : 22.6
HRN : 12.8
어떤 스케줄링이 모든 프로세스에서 최소의 평균 대기시간을 갖는가?
:평균 대기시간 11.8로 선점 최소작업 우선 방식의 평균대기시간이 가장 작다.
스케줄링의 목적을 기술하시오.
:자원 할당의 공정성 보장하며 단위 시간당 처리량 최대화한다. 또한 오버헤드를 최소화하고 자원 사용의 균형 유지 등 최대한 효율적으로 결과를 내기 위함이다.
스케줄링의 성능 기준 요소를 기술하시오.
: 사용률과 처리율, 최대화 반환시간 최소화, 대기시간 최소화, 반응 시간 최소화
다단계 피드백 큐 스케줄링 알고리즘과 전면 작업에는 라운드 로빈(순환 할당) 스케줄링 을 사용하고, 후면 작업에는 선점 우선순위 알고리즘을 사용하는 다단계 큐(전면-후면) 프로 세서 스케줄링 알고리즘의 차이를 설명하시오.
:다단계 귀환 스케줄링은 작업이 큐 사이를 이동 가능하며 서로 다른 프로세서 버스트 특성에 따라 분리 구분한다. 작업이 요구하는 프로세서 시간이 너무 크면 낮은 단계 큐로 이동 하고 입출력 중심작업과 전면 작업을 높은 우선순위 큐로 이동 하는 반면 낮은 우선순위 큐에서 오래 기다린 작업은 높은 우선순위 큐로 이동한다.
다단계 큐는 작업이 한 큐에만 고정되어 실행되며 큐 사이에 옮겨지지 않는다. 전면 작업과 후면 작업의 성질을 바꿀 수 없다. 그리고 스케줄링 부담이 적은 장점이 있으나 융통성이 적다
2016년 10월 9일 일요일
식사하는 철학자
#include <stdio.h> #include <pthread.h> #define NUM_THREADS 5 pthread_mutex_t mutexes[NUM_THREADS];pthread_cond_t conditionVars[NUM_THREADS];int permits[NUM_THREADS];pthread_t tids[NUM_THREADS];void pickup_forks(int philosopher_number) { pthread_mutex_lock(&mutexes[philosopher_number%NUM_THREADS]); while (permits[philosopher_number%NUM_THREADS] == 0) { pthread_cond_wait(&conditionVars[philosopher_number%NUM_THREADS], &mutexes[philosopher_number%NUM_THREADS]); } permits[philosopher_number%NUM_THREADS] = 0; pthread_mutex_unlock(&mutexes[philosopher_number%NUM_THREADS]);}void return_forks(int philosopher_number) { pthread_mutex_lock(&mutexes[philosopher_number%NUM_THREADS]); permits[philosopher_number%NUM_THREADS] = 1; pthread_cond_signal(&conditionVars[philosopher_number%NUM_THREADS]); pthread_mutex_unlock(&mutexes[philosopher_number%NUM_THREADS]); }void* Philosopher(void * arg) { int philosopher_number; philosopher_number = (int)arg; // pickup left fork pickup_forks(philosopher_number); printf("philosopher(%d) picks up the fork(%d).\n", philosopher_number, philosopher_number); // pickup right fork pickup_forks(philosopher_number+1); printf("philosopher(%d) picks up the fork(%d).\n", philosopher_number, (philosopher_number + 1) % NUM_THREADS); printf("philosopher(%d) starts eating \n", philosopher_number); sleep(2); printf("philosopher(%d) finishes eating \n", philosopher_number); // putdown right fork return_forks(philosopher_number + 1); printf("philosopher(%d) put down the fork(%d).\n", philosopher_number, (philosopher_number + 1) % NUM_THREADS); // putdown left fork return_forks(philosopher_number); printf("philosopher(%d) put down the fork(%d).\n", philosopher_number, philosopher_number); return NULL;}void * OddPhilosopher(void * arg) { int philosopher_number; philosopher_number = (int)arg; // pickup right fork pickup_forks(philosopher_number + 1); printf("philosopher(%d) picks up the fork(%d).\n", philosopher_number, (philosopher_number + 1) % NUM_THREADS); // pickup left fork pickup_forks(philosopher_number); printf("philosopher(%d) picks up the fork(%d).\n", philosopher_number, philosopher_number); printf("philosopher(%d) starts eating \n", philosopher_number); sleep(2); printf("philosopher(%d) finishes eating \n", philosopher_number); // putdown left fork return_forks(philosopher_number); printf("philosopher(%d) puts down the fork(%d).\n", philosopher_number, philosopher_number); // putdown right fork return_forks(philosopher_number + 1); printf("philosopher(%d) puts down the fork(%d).\n", philosopher_number, (philosopher_number + 1) % NUM_THREADS); return NULL;}int main() { int i; for (i = 0; i < NUM_THREADS; i++) { pthread_mutex_init(&mutexes[i], NULL); pthread_cond_init(&conditionVars[i], NULL); permits[i] = 1; } for (i = 0; i < NUM_THREADS; i++) { if (i % 2) { pthread_create(&tids[i], NULL, OddPhilosopher, (void*)(i)); } else{ pthread_create(&tids[i], NULL, Philosopher, (void*)(i)); } } for (i = 0; i < NUM_THREADS; i++) { pthread_join(tids[i], NULL); } for (i = 0; i < NUM_THREADS; i++) { pthread_mutex_destroy(&mutexes[i]); pthread_cond_destroy(&conditionVars[i]); } return 0;}
피드 구독하기:
덧글 (Atom)